The advancements in AI technology have gone beyond our imagination. The AI can generate realistic images and read text aloud with the TTS tool. Also, real-time voice cloning technology has made a significant impact in today's world. You can transform plain text into lifelike AI-generated speech in various languages. It perfectly mimics the voice of another person and can read the text with accuracy.
Moreover, it uses neural networks and speech synthesis that can assist in complex domains. In this article, we'll explore some repositories of real-time voice cloning GitHub.
In this article
Part 1: An Introduction to Real-Time Voice Cloning
Real-time voice cloning uses generative models to create real human voices. The building blocks are speech synthesis, voice embedding, and waveform generation. Also, the AI is trained to gather data on a set of human voice samples to generate authentic results. It gathers and learns how we talk - our pitch, rhythm, and voice quirks.
This voice cloning technology works on four models that enable real-time voice cloning. These models are text-to-Mel coder, speaker encoder, synthesizer, and vocoder. Real-time voice cloning software has been integrated into various tools and platforms.
Functions of Real-Time Voice Cloning
- Real-time voice clone AI as a virtual assistant can sound like your desired celebrity. You can customize your assistant's voice with voices like Lady Terresa or Elon Musk.
- Entertainment industries use real-time voice cloning softwareto create character voiceovers. From video games to animated movies, this technology makes it easy. Also, this creates an immersive and engaging environment for players and viewers.
- This technology provides a voice to all the speech-disabled people. The tool can provide a synthetic voice to these people and improve their lives. Also, people with speech impairment can regain their confidence by having the ability to communicate.
- Businesses can improve their customer service by using real-time voice cloning online. They can strengthen their brand name by giving their chatbot a synthetic voiceover. This way, your customers will be engaged with the chatbot and can relate to it.
Part 2: Finding The Best Real-Time Voice Cloning from GitHub
GitHub has many repositories that can help users perform various tasks. You can find different projects to reshape real-time voice creation. It offers one-shot cloning, better style transfer, and smooth text-to-speech models. Now, let's explore a repository for real-time voice cloning to make voices sound natural.
Top-Rated Real-Time Voice Cloning Tools From GitHub:
1. Real-Time Voice Cloning (CorentinJ)
Users can explore this repository to clone their voice within 5 seconds. This real-time voice cloning GitHub repository is an implementation of the SV2TTS framework. SV2TTS uses a three-stage deep learning process to carry out voice cloning. This implementation creates a digital voice representation from a brief audio sample. Then, it utilizes this sample to generate diverse speech from the given text.
- Install Requirements:
To install it on your system, it's better to have a stable GPU for a smooth experience. Other than this, you should have at least Python 3.5 for the repository to function properly. Also, it is necessary to install ffmpeg files to process audio files.
2. PaddleSpeech
It is an exceptional open-source toolkit on the Paddle-Paddle platform. With this simple toolkit, you can perform a variety of audio-related tasks. It employs new cutting-edge technology and production-ready streaming ASR and TTS systems. Plus, this repository provides fast-processing models to the users. PaddleSpeech also utilizes self-defined linguistics to adapt to the Chinese context.
This repository aims to inspire industrial and academic fields through its several modules. These may include Automatic Speech Recognition, Keyword Spotting, Speech Translation, etc. PaddleSpeech also combines its task with various other fields, including NLP and Computer Vision.
3. Multi-Tacotron Voice Cloning
Multi-Tacotron is the ultimate in voice cloning with multilingual implementation. You can make use of this repository for Russian and English languages. This repository builds upon real-time voice cloning online with a four-stage learning framework. With a few seconds of audio, it crafts a numerical representation of a voice. Furthermore, it uses this audio to condition a text-to-speech model.
For cloning the English language, the original implementation is enough. You don't require a high-tier GPU to run this toolbox; even a low-tier one will work well. There are also some pre-trained models for datasets that you can download with ease.
4. Coqui TTS
You can explore the finest text-to-speech toolkit with Coqui. Boasting high-performance models, it covers TTS tasks effortlessly. This repository extends its ability with speaker encoder for various Vocoder models. With swift model training and multi-speaker TTS support, it stands out for efficiency. TTS version 2 now has 16 more languages and better overall performance.
Moreover, TTS can now work smoothly with even less than 200ms latency. More than 1100 languages are supported with pre-trained models of this repository. Plus, all TTS models are ready to use with efficient model training.
5. Multilingual Text-to-Speech (Tomiinek)
This repository available on GitHub is an implementation of Tacotron 2. It supports code-switching, voice cloning, and parameter-sharing for versatile experiments. You can utilize training data and source code for optimized voice cloning. Also, it compares three models for multilingual synthesis. This repo also has samples generated by a monolingual vanilla Tacotron.
Additionally, multilingual Text-to-Speech comes with a convolutional encoder with parameters that are language-specific. There are also some interactive demos that introduce code-switching abilities and provide multilingual training on the model.
6. One-Shot Voice Cloning CMsmartvoice
One-shot voice cloning with Unet-TTS features a powerful speaker and style transfer capabilities. The repository generates text sounds with provided inferencing code and pre-training models. Its model training focuses on neutral emotion to avoid strong emotional speech. Also, it addresses the challenges of out-of-domain style using the Unet network and AdaIN layer.
Users are not required to use reference speech if they plan to do one-shot voice cloning. Also, the requirement to manually enter statistics of duration is no longer essential. Only Linux users can install it with the correct TensorFlow and TensorFlow-addons versions.
7. Voice-Synthesis (smoke-trees)
This approach creates a numerical representation of a voice from a few seconds of audio. Then, it uses this audio for text-to-speech synthesis. SV2TTS excels with deep learning and uses a speaker encoder, synthesizer, and voice coder. It clones voices in real time with zero-shot learning. The repository identifies voices, and the synthesizer generates Mel-spectrograms from the text. Finally, the vocoder turns them into lifelike waveforms.
All you need to do is feed this repository your voice sample or custom voice, and it can synthesize a clone of it for you. You can also use a microphone to input your text commands through speech. There are also instructions given if you want to work with your own models on different datasets and language mediums.
8. VoiceSmith (dunky11)
VoiceSmith is an easy-to-use repository requiring no coding experience. It fine-tunes a pipeline based on Delightful TTS and UnivNet for single or many speakers. Users can opt from a proprietary 5000 speaker dataset with automatic text normalization. Windows and Linux are supported, and an NVIDIA GPU with CUDA support is for faster training. Docker is essential for seamless operation for users exploring real-time voice cloning online.
- Install Requirements:
A RAM of less than 8GB may not work well with it, so it’s better to use at least 8GB RAM. To use this repository on Linux, you are advised to install Docker Engine. Users also get to play around with an emotional 60-speaker dataset-trained model.
9. Voice Cloning App by BenAAndrew
This Python or Pytorch repository empowers users for effortless voice synthesis. You can enjoy automatic dataset creation, multi-language support, and easy remote training. It allows you to build datasets and proceed further by using a training model. The tool offers new datasets and lets you extend existing datasets for voice cloning. This simple approach elevates your experience of real-time voice cloning on GitHub.
In future improvements, this repository is expected to support AMD GPU for better performance. Also, it claims to improve its batch size estimation. You can run it on Windows 10 or Ubuntu 20.04 operating system with at least 5GB of required disk space.
10. Unet-TTS
Unet-TTS excels in unseen speaker and style transfer for one-shot voice cloning. It works in seconds to produce target audio through voice synthesis without fine-tuning. There are various speaking styles embedded in a seamless way. Its algorithm works on a skip-connected structure to capture speaker and utterance features. Users can get precise inferences of complex voice characteristics and speaking styles.
However, it’s still a challenging task to perform out-of-domain transfer. According to the similarity evaluation, the new model excels in speaker embedding and style modeling. The new model can also discover utterance-level details from the reference audio.
Part 3: Master the Art of AI Voice with Wondershare Virbo


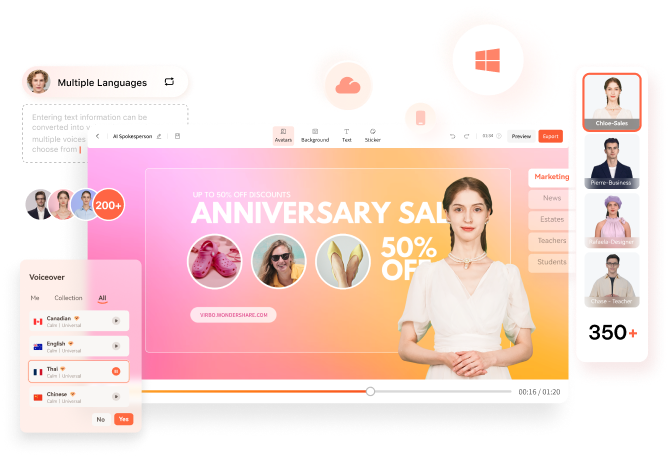
If you want to create AI voices for your content creation purpose, there is a solution. Wondershare Virbo provides real-time voice cloning services to you. With the help of this tool, you can create lifelike AI voices from text. You can create AI voices in different languages for your podcast with this tool.
The tool is diverse as it allows you to choose the gender of your created voice. Users can easily input text to generate the AI voices. It is cost-effective and provides high-quality audio. An influencer or a content creator can engage viewers through this real-time voice clone tool. This tool matches all your needs related to voice clone services.
Key Features of Wondershare Virbo
- AI Streamer: You can increase the sales of your online shop with the newly released live streaming tool. It provides AI-avatar to increase revenue during live shopping. With 24/7 AI streaming and multilingual avatars, you can transform the live experience.
- AI Script Generator: The user can use this feature of the tool to generate a script for the video. With this auto-generated script functionality, users can generate scripts instantly. Also, it provides the option to select the language of the video script.
- AI Video Translator: Virbo allows you to break the language barrier with this feature. The AI video translator feature can translate video content into 20+ languages. This is an affordable way to convert the content to other languages.
- AI Talking Photo: Social media influencers can impress their follower with AI talking photo features. It allows you to add voice clips to any photo to make them interactive. You can use this new way of storytelling to engage your viewers.
Comprehensive Step Guide to Use Virbo’s AI Voice Feature
Now, you get familiar with all the features of the tool besides voice cloning. The tool is an all-in-one platform to generate and share content. Let's go through the following easy steps to use this tool.
Step 1 Install Wondershare Virbo and Create a Video
Start the process by launching and installing Virbo on your desktop. You can also get direct access to Virbo’s exceptional platform online through a browser. Then, click the “Create Video” button on the main interface of this tool. Afterward, choose the video aspect ratio of the video and press the "Create Video" button again.

Get Started Online Try in App Free
Step 2 Add the Text Script for the Video Setting
Now, with your chosen avatar, you get access to a new window. After this, in the “Text Script” section, write your personalized narrative. Then, you can adjust the volume, pitch, and speed of your cloned voice.

Step 3 Change the Voiceover Setting and Export the Video
Afterward, press the “Language” button over the volume setting to change the AI avatar voice. Next, you get the pop-up window to choose the gender, language, and narrator of the video. Once you are done with these changes, click the “OK” button. Finally, save the video with cloned voice by hitting the “Export” button on the top right corner.

Conclusion
In the end, we have learned that real-time voice cloning software can help you in various areas of life. This AI technology is used in business industries and for personal experience. For this purpose, it is only a matter of finding the best software for voice cloning. Wondershare Virbo is your best option for real-time voice cloning online to generate human-like voices.
*Note: The AI voice cloning technology mentioned in this page is for lawful use only. Unauthorized replication or commercial use of others' voices is prohibited. Violators will be held legally accountable.